I attended the ‘Global Graph’ session at the #cetis09 conference and made a largely failed attempt to demo some of the work we’ve been doing with Triplify and the Talis Platform. (In my defence, it wasn’t a planned demo and jiscpress.org was down while Alex was doing some design work).
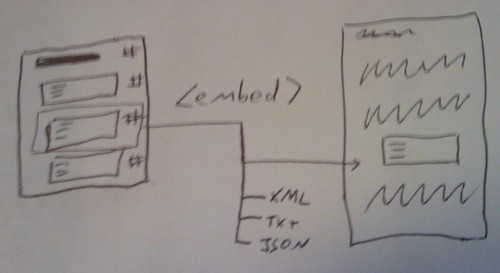
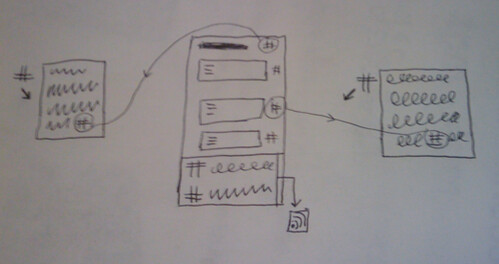
Anyway, what I would have shown was how each document site on jiscpress.org uses Triplify to provide Linked Data in the form of RDF/N3 triples, which we store on the Talis Platform using a plugin Alex wrote.
Using Alex’s config file for WordPress MultiUser, we drop the triplify directory into the WPMU root directory, alongside wp-admin, wp-includes and all the other WordPress files. You should take a look at the config file and make sure it’s doing what you want it to do, but it will work as it is. With this in place, Linked Data in the form of an RDF flat file for each document site (blog) is available at http://document.jiscpress.org/triplify or http://jiscpress.org/document/?triplify
(I should warn you that none of the URLs in this post are genuine URLs. They’re examples of syntax. The server at jiscpress.org will stop running at the end of December).
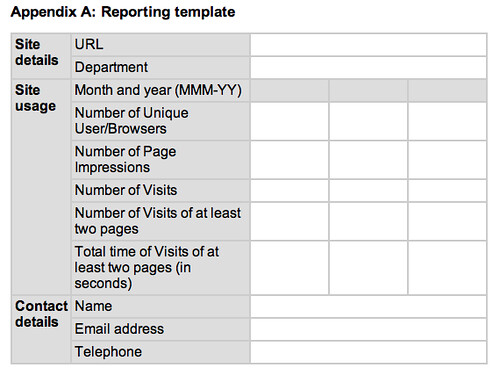
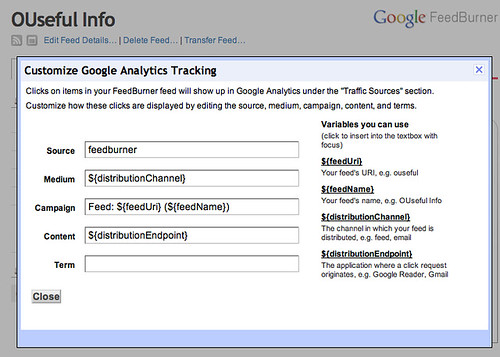
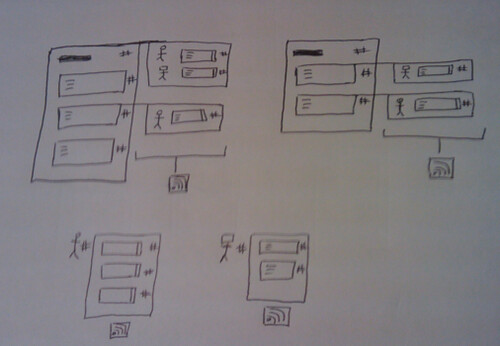
Now, to get that same data onto the Talis Platform, Alex has written a plugin for WPMU that periodically crawls the documents for changes and pushes the new data to a Talis Platform account. Here are the WPMU site-wide admin options:

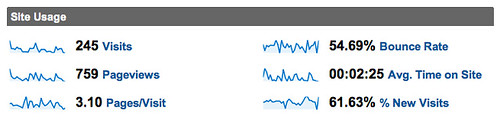
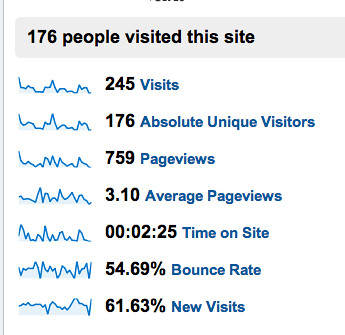
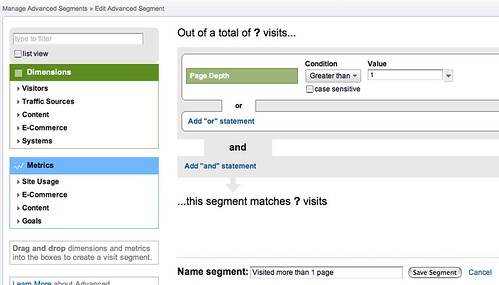
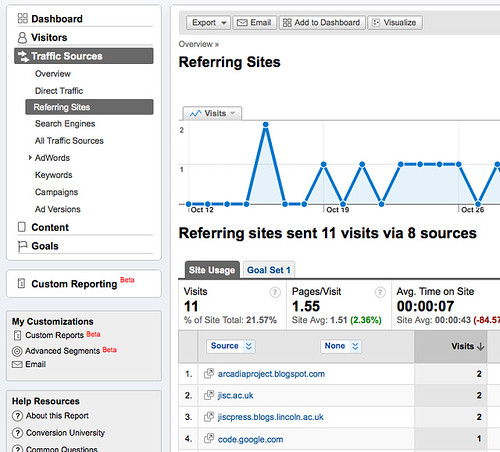
and here are the per document site user settings:

I won’t explain what the plugin does in detail. Just click on those images above and you’ll see the options that are available and if you’re reading this stuff, you know what it’s all about. The Talis/Triplify plugin for WPMU will appear on http://wordpress.org/extend/plugins in the next couple of weeks. It’s been tested and it does what we expect it to do but we want to test it more on sub-directory installs before it’s publicly available. Full documentation will appear soon on http://code.google.com/p/jiscpress/wiki/Documentation
We have also developed a WPMU plugin for Open Calais and the Yahoo! Term Extraction API. This provides a background service which indexes each document section (blog post) and creates relationships between content across the platform. We’ll post here about that very soon.
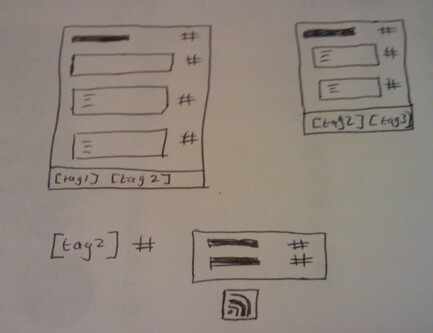
In addition to the Linked Data, JISCPress, using digress.it on WordPress, provides a long list of other open data (not Linked Data) end-points which might be put to good use. Here you go..
Document paragraphs
These are switches that provide individual paragraph data in different formats.
http://test.jiscpress.org/?p=15&digressit-embed=1&format=xml
http://test.jiscpress.org/?p=15&digressit-embed=1&format=text
http://test.jiscpress.org/?p=15&digressit-embed=1&format=rss
http://test.jiscpress.org/?p=15&digressit-embed=1&format=html
http://test.jiscpress.org/?p=15&digressit-embed=1&format=json
Document sections
This is just the regular WordPress post content in RSS format. In JISCPress terms, it’s the document section which is a single feed item.
http://test.jiscpress.org/2009/07/28/6-how-jisc-invests/feed/?withoutcomments=1
and this is the normal WordPress feed of comments on a particular post/document section.
http://test.jiscpress.org/2009/07/28/6-how-jisc-invests/feed/
We’ve also added the provision of a feed for each document section (‘post’), where each paragraph is a feed item. Note that this makes digress.it a nice tool for building your own feeds out of a single WordPress post.
http://test.jiscpress.org/feed/paragraphlevel/3-jisc-vision-mission-and-objectives/
Per paragraph comments/discussions
For each paragraph, there’s a feed of the comments/discussion.
http://test.jiscpress.org/feed/paragraphcomments/3-jisc-vision-mission-and-objectives,1
Commenter feeds
For each person that comments, there’s a feed of their comments
http://test.jiscpress.org/feed/usercomments/Joss%20Winn
All the other stuff
Don’t forget that the entire document content is also available as a feed
http://test.jiscpress.org/feed/
http://test.jiscpress.org/feed/rss
http://test.jiscpress.org/feed/rss2
http://test.jiscpress.org/feed/atom
http://test.jiscpress.org/feed/rdf
as are all comments from the site, too:
http://test.jiscpress.org/comments/feed
with WordPress, tags also have feeds
http://test.jiscpress.org/tag/tag1/feed
and so do categories
http://test.jiscpress.org/category/category1/feed
You can also combine tags
http://test.jiscpress.org/tag/tag1+tag2+tag3/feed
and you can combine tags and categories
http://test.jiscpress.org/?category_name=category1&tag=tag2,tag3&feed=rss2
Finally, authors have a feed, too
http://test.jiscpress.org/author/joss/feed/
Summary
WordPress is a versatile CMS for organising/designing and publishing data as feeds and therefore a useful source of Open Data. JISCPress has extended this versatility by choosing to develop further data end points using digress.it and offering a simple way of publishing Linked Data to the Talis Platform RDF triple store where is can be queried and mashed up using the platform’s API.