One of the things we didn’t put into the original JISCPress bid – though in hindsight we might have – was a use case for commentable documents in the context of government consultations soliciting formal responses from higher education institutions (for example, Universities UK: Review of External Examining Arrangements in the UK).
From a chat with Alison Nash in the OU’s recently reorganised Strategy Unit (I think?), it seems that candidate consultations are fielded by a member of that unit who then emails likely suspects (identified quite how, I’m not sure?) with either a link to, or copy of, the consultation document; (these are typically Word or PDF documents). As with many of the consultations we have looked at in the context of Write To Reply, the consultations typically have a set of questions associated with them that are distributed throughout the consultation document as a whole. Comments and responses to questions are then returned by email (I didn’t ask whether this is typically in the body of an email message, in a Word document, or as comments or highlighted changes on a copy of the orginal consultation), collated (again, I’m not sure how? One way would be to use a spreasheet, with rows for respondent and columns for each question (or vice versa)), and used to frame the institutional response. (I’m not sure if a draft of the institutional response was then circulated to the orginal commenters for final comment…?) The question that was then asked was: would a WriteToReply style approach be appropriate for managing returns of comments and answers to consultation questions in a rather more organised way than is currently the case?
(If anyone from the OU, or other HEIs who engage in producing formal instituional responses to consultations would like to provide further detail about the workflow for soliciting internal comments, producing drft and final versions of instituional responses, and then tracking the impact of comments made in the response, please post a comment to this post…)
Here are some thoughts/matters arising relating to how the WriteToReply/JISCPress/digress.it approach might apply:
– comments may need to be private; this could be achieved by hosting WordPress within the firewall, limiting who can view comments to members of the institution, or not making comments public (e.g. by moderating them, meaning that only the blog owner could see them). Limiting who can make comments can be achieved by requiring users to log in to the blog, and only providing certain users with log in accounts.
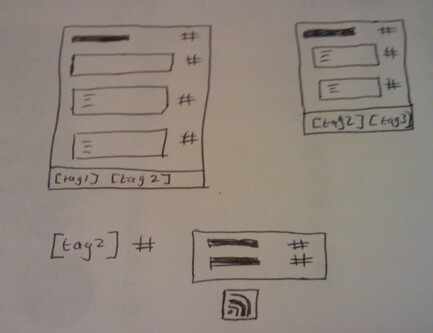
– it may not be appropriate to allowing commenting on all paragraphs, instead requiring users to only comment on actual questions. This might be achieved by disabling comments on all pages except a single summary page that contains one paragraph per question, maybe with links back to the actual posts that contain the question in context.
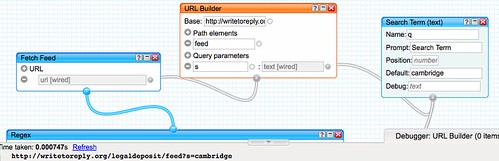
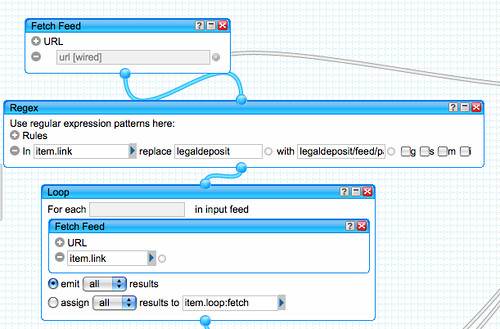
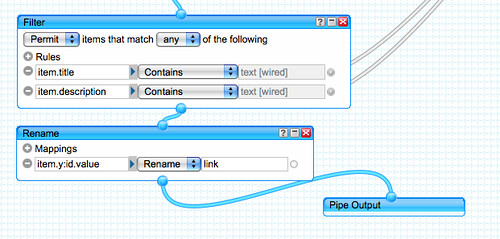
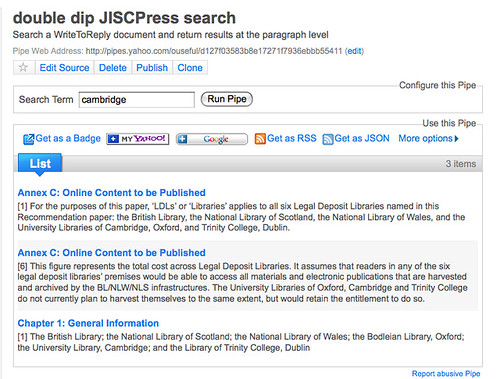
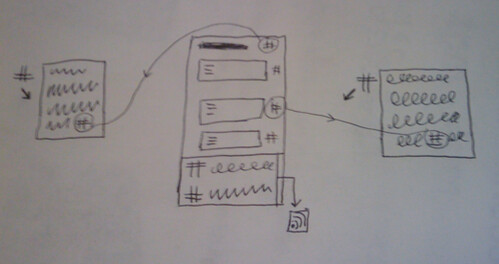
– if comments are solicited throughout the document, a dashboard tool such as Netvibes can be used to aggregate comments from different sections of the document; tools like Yahoo Pipes can also be used to aggregate comments from separate areas of the document and display them in a single view. Views over comments by individual commenters are also available and may be collated together on dashboard pages (for example, with separate pages aggregating comments from different sorts of commenter – e.g. allowing views over responses by Faculty, for example).
– once a formal response has been produced, it may be appropriate it post it on the consultation site to allow commenters to see how their comments were o weren’t integrated in to the official response (maybe leaving it open to them to submit a personal response to the consultation if they feel their views were not appropriately reflected, if at all. (The more I think about the process of these document based consultations, the more I feel a feedback loop is required that allows folk to see what sort of impact, if any, their comments may have had. I also briefly touched on this in On the Different Roles Documents and Comments May Take in a Commentable Document.) The consultation document site then becomes an important part of institutional memory, archiving as it does the original consultation, individual comments from members of the institution, and the institution’s formal response. It might also be the case that a draft of the institutional response is placed on the same site and comments on it solicited. (The site would then be hosting documents in two modes – the original consultation mode document, and then a draft mode document (again, this distinction appears in the Different Roles blog post.)
In many cases, it might be that the paragraph level commenting approach is not appropriate – unless comments are limited to just the consultation questions themselves, each as a separate commentable item. Where it is appropriate to isolate consultation questions from the surrounding text, a simple form may provide the best way of capturing comments.
In the OU, where I believe we are about to start rolling out Google Apps for Education to at least some of our students over the next month or two, it might be appropriate to look at using a Google form as platfrom for capturing comments. As well as satisfying the immediate goal (capture comments in a centralised way), this approach would also provide a legitimate and low risk use case for exloring how we might make use of the Google Apps environment as part of internal business processes.
The simplest case, then, would be for the internal staff member responsible for gathering comments to create a Google form. I don’t know if internal staff members have yet been issued with login details for how to access Google Apps on the open.ac.uk domain, but in the interim they can either create a personal Google account (or I could let them have an account on one of my Google apps domains!). Creating a form can be done either from the main docs menu, or within a Google spreadsheet (the posted form results are collated within a spreadsheet).

For most consultations based around a set of specific questions, the format of the form would look something like this:
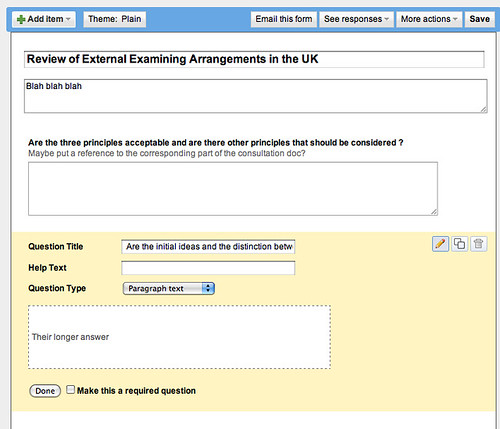
That is, a copy and pasted copy of each consultation question (with minor tweaks so the question makes sense in a standalone questionnaire) as a separate form item, with a Paragraph text element for the response.
If additional commentary is required, the section head (which includes a description component) can be used to display it:
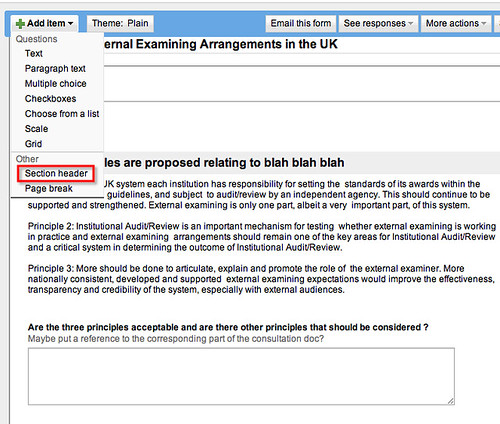
It might also be worth capturing “any other comments” in a final paragraph text comment at the end of the questionnaire.
Although the form, once published, would be open to anyone on the apps domain, (if they knew the URL), a further “security” measure would be to prompt the user for a consultation “pass phrase” emailed to them as part of the request for comments (“please enter this keyphrase when you complete the form so we can put your responses into the class of ‘high priority’ responses”;-) This might even be a required element.
Alternatively, a keyphrase element could be used to sort the responses in the results spreadsheet, or as suggested above in the context of digress.it, used to sort responses for example by Faculty, (Alternatively, an optional unique key code be be generated for each invited response to identify their responses. Or we could request an OU identifier, name, email address etc to track who made what comment (though these approaches are gameable and don’t necessarily imply that the person with a given identifier is the person who submitted the form…)). If users are logged in to the Google Apps environment, it may be that their identity is recorded anyway…? Hmm….
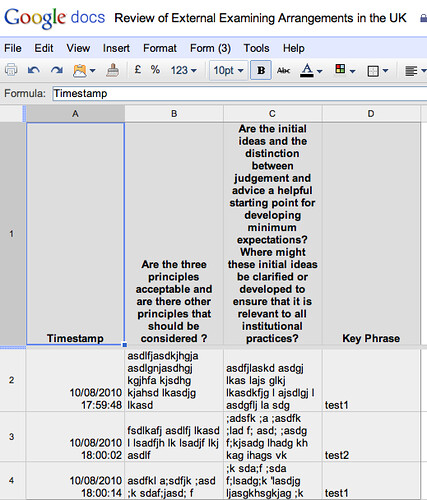
For just collecting responses, pretty much anyone could just set up the form and then email the link to the form to the potential commenters. With the availability of Google Apps script, and a little bit of developer time, it would also be possible to provide alerts to the internal consultation organiser whenever a form submission is made, provide automated collation of responses by question and pop these into a Google wordprocessor doc (I think…?!) and even manage a circulation list – so for example, a list of respondents could be created in a spreadsheet, used to mail out invitations for them to complete the form, and then track their response. In the advent of them not responding within a certain period, an automated reminder could be sent out. (I’m guessing it would take about a day to build and test such a workflow, which once created would be reusable.)
Another advantage of using the Google Apps approach would be that the response spreadsheet (or an automagically maintained Google wordprocessor doc version of it) could be shared to other members of the team providing the formal institutional response as an online shared document appearing in each individual’s Google docs “inbox”.
PS it seems that within a Google Apps for Edu environment, it may now also be possible for users to edit their form responses if they want to revise their answers…
PPS it’s also worth noting here a couple of practical considerations about how to write a consultation document bearing in mind that someone might put together a form to collate the responses. Firstly, the question should make sense as a standalone item (i.e. out of context) or very clearly identify what it is referring to rather than just “the above”. Secondly, if the questions are collated together in a single appendix, it makes it easier to just check off that each question has been included in the form. (It’s also handy as a one page item for someone who is putting together the response.) Links to the original context also help; (in a sense, this sort of Appendix is like “List of Tables” or “List of Figures” that acts as contents page for locating questions within the document). Reading over the questions in an Appendix will also make it obvious whether or not the question was written in such a way that it implicitly refers to content surrounding it in the original embedded context (“see the above” again…) Note that I’m not saying questions shouldn’t be embedded, just that when they are taken out of context, they still make sense and read well. In the example I give above about external examiners, the questions had to be tweaked so that they made sense as standalone items.







![]()